Information and Communications Engineering News
"Lens-less" Imaging Through Advanced Machine Learning for Next Generation Image Sensing Solutions
In a significant development for "lens-less" imaging, a research team from the School of Engineering, Tokyo Institute of Technology (Tokyo Tech), has devised a new image reconstruction method that enables high-quality imaging in a short computing time. The new method is based on a leading-edge machine learning technique, called Vision Transformer, contributes greatly to the practical application of a "lens-less" camera.
A camera usually requires a lens system to capture a focused image, and the lensed camera has been the dominant imaging solution for centuries. A lensed camera requires a complex lens system to achieve high-quality, bright, and aberration-free imaging. Recent decades have seen a surge in the demand for smaller, lighter, and cheaper cameras. There is a clear need for next-generation cameras with high functionality, which are compact enough to be installed anywhere. However, the miniaturization of the lensed camera is restricted by the lens system and the focusing distance required by refractive lenses.
Recent advances in computing technology can simplify the lens system by substituting some parts of the optical system with computing. The entire lens can be abandoned thanks to the use of image reconstruction computing, allowing for a lens-less camera, which is ultra-thin, lightweight, and low-cost. The lens-less camera is gaining traction recently. But thus far, the image reconstruction technique has not been established, resulting in inadequate imaging quality and tedious computation time for the lens-less camera.
Recently, researchers have developed a new image reconstruction method that improves computation time and provides high-quality images. Describing the initial motivation behind the research, a core member of the research team, Prof. Masahiro Yamaguchi of Tokyo Tech, says, "Without the limitations of a lens, the lens-less camera could be ultra-miniature, which could allow new applications that are beyond our imagination." Their work has been published in Optics Letters![]() .
.
The typical optical hardware of the lens-less camera simply consists of a thin mask and an image sensor. The image is then reconstructed using a mathematical algorithm, as shown in Fig. 1. The mask and the sensor can be fabricated together in established semiconductor manufacturing processes for future production. The mask optically encodes the incident light and casts patterns on the sensor. Though the casted patterns are completely non-interpretable to the human eye, they can be decoded with explicit knowledge of the optical system.

Figure 1. Pipeline of the lens-less imaging
-
A schematic of the how the lens-less imaging process works, from light collection through encoding the signal to post-processing with computing algorithms.
Image credit: Xiuxi Pan from Tokyo Tech
However, the decoding process—based on image reconstruction technology—remains challenging. Traditional model-based decoding methods approximate the physical process of the lens-less optics and reconstruct the image by solving a "convex" optimization problem. This means the reconstruction result is susceptible to the imperfect approximations of the physical model. Moreover, the computation needed for solving the optimization problem is time-consuming because it requires iterative calculation. Deep learning could help avoid the limitations of model-based decoding, since it can learn the model and decode the image by a non-iterative direct process instead. However, existing deep learning methods for lens-less imaging, which utilize a convolutional neural network (CNN), cannot produce good-quality images. They are inefficient because CNN processes the image based on the relationships of neighboring, "local", pixels, whereas lens-less optics transform local information in the scene into overlapping "global" information on all the pixels of the image sensor, through a property called "multiplexing".
The TokyoTech research team is studying this multiplexing property and have now proposed a novel, dedicated machine learning algorithm for image reconstruction. The proposed algorithm, shown in Fig. 2, is based on a leading-edge machine learning technique called Vision Transformer (ViT), which is better at global feature reasoning. The novelty of the algorithm lies in the structure of the multistage transformer blocks with overlapped "patchify" modules. This allows it to efficiently learn image features in a hierarchical representation. Consequently, the proposed method can well address the multiplexing property and avoid the limitations of conventional CNN-based deep learning, allowing better image reconstruction.
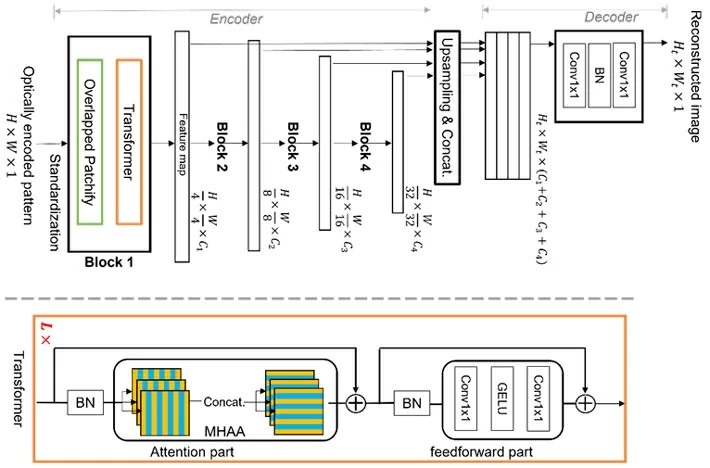
Figure 2. The Proposed ViT-based neural network for image reconstruction.
-
Vision Transformer (ViT) is leading-edge machine learning technique, which is better at global feature reasoning due to its novel structure of the multistage transformer blocks with overlapped ‘patchify’ modules. This allows it to efficiently learn image features in a hierarchical representation, making it able to address the multiplexing property and avoid the limitations of conventional CNN-based deep learning, thereby allowing better image reconstruction.
Image credit: Xiuxi Pan from Tokyo Tech
While conventional model-based methods require long computation times for iterative processing, the proposed method is faster because the direct reconstruction is possible with an iterative-free processing algorithm designed by machine learning. The influence of model approximation errors is also dramatically reduced because the machine learning system learns the physical model. Furthermore, the proposed ViT-based method uses global features in the image and is suitable for processing casted patterns over a wide area on the image sensor, whereas conventional machine learning-based decoding methods mainly learn local relationships by CNN.
In summary, the proposed method solves the limitations of conventional methods such as iterative image reconstruction-based processing and CNN-based machine learning with the ViT architecture, enabling the acquisition of high-quality images in a short computing time. The research team further performed optical experiments—as reported in their latest publication in—which suggest that the lens-less camera with the proposed reconstruction method can produce high-quality and visually appealing images while the speed of post-processing computation is high enough for real-time capture. The assembled lens-less camera and the experimental results are shown in Fig. 3 and Fig. 4, respectively.

Figure 3. Assembled lens-less camera used for optical experiment.
-
The lens-less camera consists of a mask and an image sensor with a 2.5 mm separation distance. The mask is fabricated by chromium deposition in a synthetic-silica plate with an aperture size of 40×40 μm.
Image credit: Xiuxi Pan from Tokyo Tech

Figure 4. Optical experiment results
-
The targets are the images displayed on an LCD screen (left two columns) and the objects in the wild (right two columns; beckoning cat doll and stuffed bear), respectively. The first row shows the ground truth images displayed on the screen and the shooting scenes for in-the-wild objects. The second row shows the captured patterns on the sensor. The last three rows illustrate the reconstructed images by the proposed, model-based, and CNN-based methods, respectively. The proposed method produces the most high-quality and visually appealing images.
Image credit: Xiuxi Pan from Tokyo Tech
"We realize that miniaturization should not be the only advantage of the lens-less camera. The lens-less camera can be applied to invisible light imaging, in which the use of a lens is impractical or even impossible. In addition, the underlying dimensionality of captured optical information by the lens-less camera is greater than two, which makes one-shot 3D imaging and post-capture refocusing possible. We are exploring more features of the lens-less camera. The ultimate goal of a lens-less camera is being miniature-yet-mighty. We are excited to be leading in this new direction for next-generation imaging and sensing solutions," says the lead author of the study, Mr. Xiuxi Pan of TokyoTech, while talking about their future work.
- Reference
| Authors : | Xiuxi Pan1, Xiao Chen1, Saori Takeyama1 and Masahiro Yamaguchi1 |
|---|---|
| Title of original paper : | Image reconstruction with Transformer for mask-based lensless imaging |
| Journal : | Optics Letters |
| DOI : | 10.1364/OL.455378 |
| Affiliations : |
1 School of Engineering, Tokyo Institute of Technology |
|
* Corresponding author's email: pan.x.aa@m.titech.ac.jp |
|
- Yamaguchi Laboratory
- Masahiro Yamaguchi | Researcher Finder - Tokyo Tech STAR Search
- Saori Takeyama | Researcher Finder - Tokyo Tech STAR Search
- Human Centered Science and Biomedical Engineering Graduate Major|Education|Department of Information and Communications Engineering, School of Engineering
- Information and Communications Engineering Graduate Major|Education|Department of Information and Communications Engineering, School of Engineering
- Information and Communications Engineering Undergraduate Major|Education|Department of Information and Communications Engineering, School of Engineering
- Latest Research News

School of Engineering
—Creating New Industries and Advancing Civilization—
Information on School of Engineering inaugurated in April 2016
Further Information
Professor Masahiro Yamaguchi
School of Engineering, Tokyo Institute of Technology
Featured News




![]()